About
Kygle is a search engine that I built upon a custom built multi-threaded C++ web-crawler that searches over an index of ~1.1 million unique web pages. The crawler ran periodically over February 6th - February 8th, 2026 achieving a max throughput of 8,500 pages per minute. Kygle’s search algorithm includes keyword ranking with BM25, Google’s Pagerank algorithm, and other custom search heuristics to provide relevant results.
Process
When I first started working on this project over winter break of my sophomore year, I did not intend for it to become a search engine. I initially worked on creating a multi-threaded web crawler to learn about writing parallel code since I was interested in it and wanted to get a head start on learning some concepts of my Introduction to Parallel and Distributed Computing class. After getting to a satisfactory spot on the crawler, I decided to create the web search engine to give a practical use to the crawler.
Crawler
When developing the crawler, I went through many iterations of how I approached the parallelism (mainly due to naiveness). For the crawler I used curl for network requests, Gumbo Parser for HTML parsing, and Libstemmer for word stemming.
The first approach I took to implement the crawler… was not a good one. I coupled both the networking and parsing part of the crawler into the same thread. Now, it was still fast, but it was not nearly as efficient as it could have been. Many threads stayed idle waiting for the network requests to come back which blocked other tasks from happening, causing a lot of wasted CPU cycles.
I then decided to use a pipeline architecture for the crawler, breaking up the different tasks of the crawler into differing threads/thread pools. Data is transferred through thread-safe queues between the different threads/thread-pools. This was much more efficient and resulted in the code becoming more modular, and easier to maintain. Curl multi handles all of the requests, a thread pool of parsers awaits responses, and then the indexer/stemming thread awaits parsed responses.
You can find a more detailed write-up on the crawler here.
Search Engine
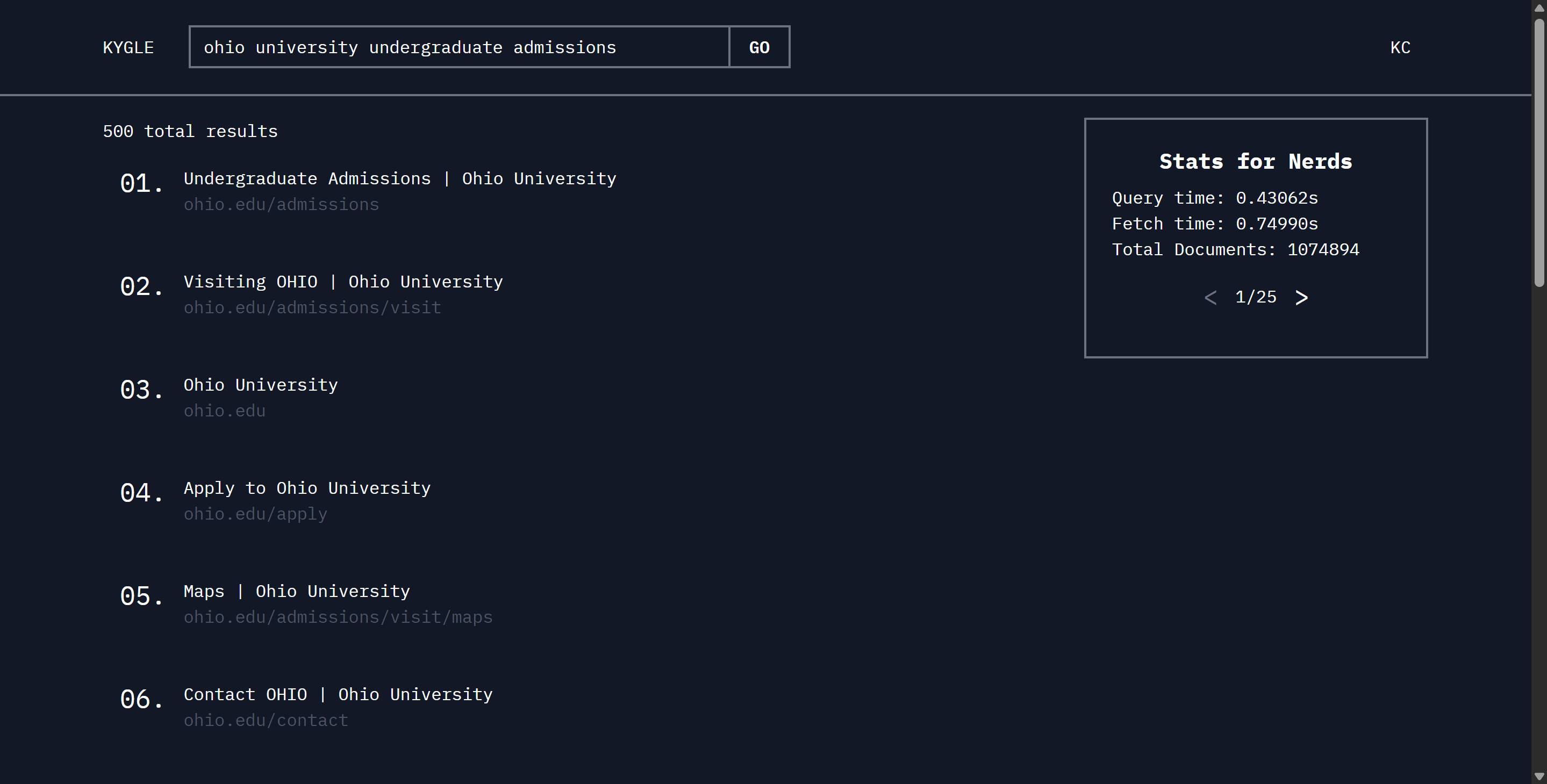
The search engine is written in Python and implements the BM25 algorithm to rank results based on word frequency. Ontop of that, it also considers a PageRank (PR) score that is pre-computed and stored in the database. I also created some custom search heuristics that consider web-page titles and URLs. Pages are preemptively narrowed down for faster results based on BM25 and PR for better performance. The breakdown of my scoring weights are as follows:
- BM25 Score (52%)
- PR Score (28%)
- URL Score (12%)
- Title Score (8%)
Solution
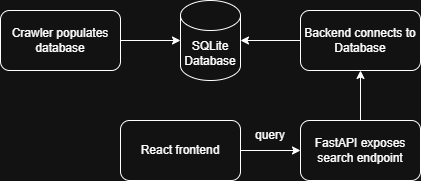
In the end, Kygle works by using the crawler to crawl a specified set of webpages and then builds an inverted index in memory before periodically flushing it to a SQLite database. The PageRank algorithm is then ran on the data in the database and writes the score to the database. A FastAPI server is responsible for serving the results to the React frontend.
Tech Stack
Crawler
- C++
- libcurl
- libstemmer
- SQLite
Search Engine
- Python (FastAPI)
- React
- SQLite